
Why Text Needs To Be Numbered
Building an LLM Part 1

In this article, we will learn why text needs to be numbered and how text is transformed into numbers. We will also cover some terminologies like tokens, embedding, why embeddings are more efficient than just tokens and why different tokenizers are different.
You might not understand some terms or concepts or claims in this article but we will understand about each concept in depth in future articles, so just be patient.
This is the first article of this “Building Your Own LLM Model” series. This series will be very long with a good amount of theory and practical projects.
The answer to the above question is really straightforward:
LLMs are a subset of Deep Learning, Deep Learning is based on optimization, learning algorithms and probabilities. These things are based on numbers. Hence, text needs to be represented as numbers.
What is a Token?
In NLP(Natural Language Processing), a token is a piece of text that can be represented by an integer. This piece of text can be a character, a subword or a word.
There are a variety of ways to break up a text into tokens and all those ways are valid.
Remember this:
“Token” is a piece of text and the integer that is associated with a token is called a “Token ID” or “Token Index”.
Why Not Just Create a Single TokenID for each character?
It is possible but there are some issues, not that crazy but still the reasons are good enough to use subwords or words as tokens:
One of the problems is that the Unicode International System recognizes over 150k characters and it keeps growing over time. This means our vocabulary would be massive and we’d need to update everything whenever new characters get added to the system.
Character level tokenization makes it harder for models to learn language patterns. Think about it: it’s way easier to learn that the word “king” is related to “queen” than to learn that the characters k-i-n-g relate to q-u-e-e-n in some meaningful way. When you tokenize at the character level, the model has to work much harder to figure out relationships between words, phrases, and concepts.
A character based tokenization scheme requires a lot of additional memory, which limits the context window. Imagine trying to process a paragraph with character-level tokens, that same paragraph uses way more tokens compared to word or subword tokenization, so you can’t fit as much text into the model’s context.
Don’t worry if you do not understand the above why part completely. I’ll go much more in depth in future articles. I’m just introducing some stuff here and giving you a rough idea of some concepts and reasoning behind them.
Now, we understood that a character based tokenization scheme is 100% possible and valid but there are some reasons due to which we have subword and word tokenization schemes.
Now, let me show you some examples of what it looks like when a sentence gets tokenized:
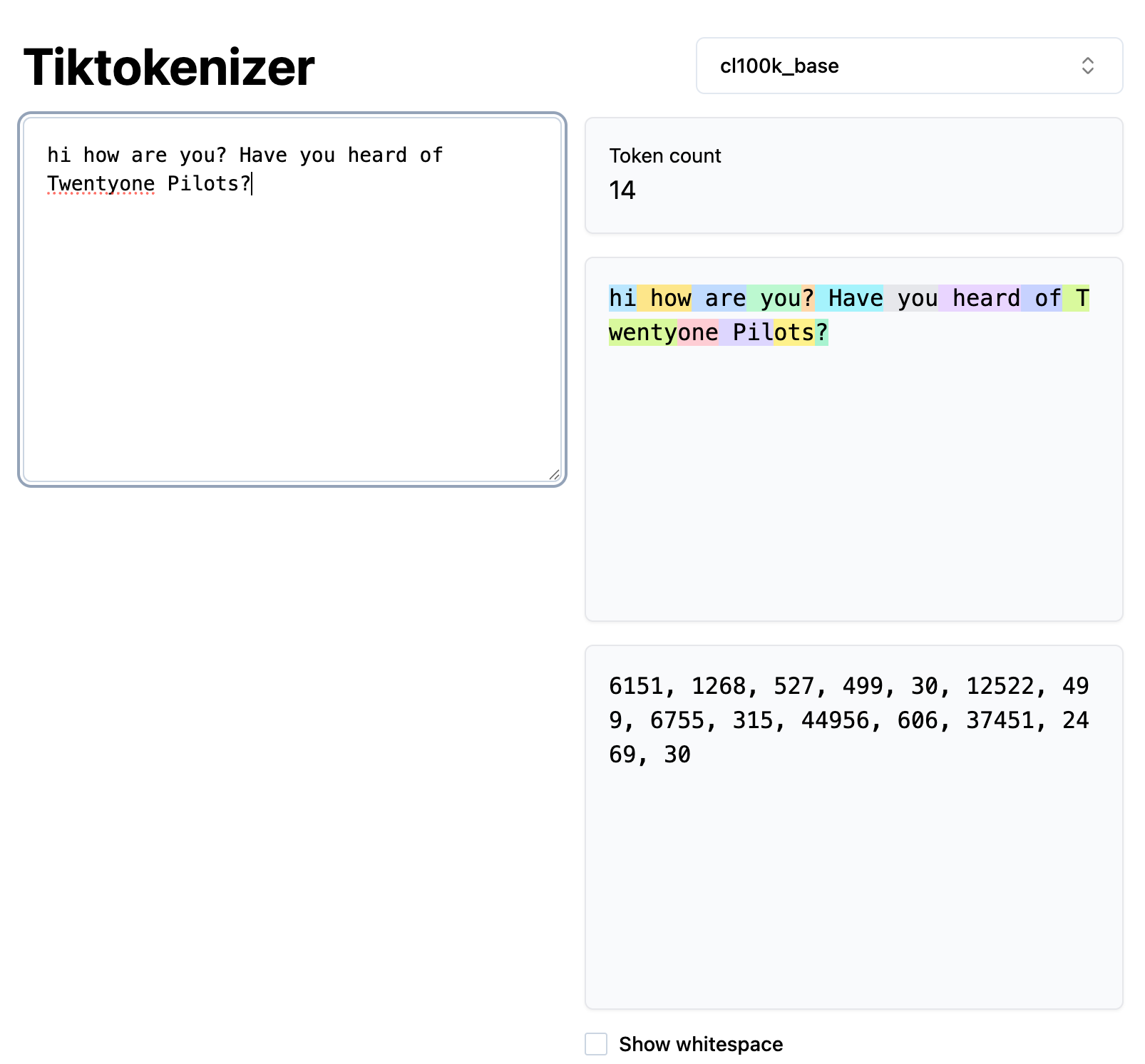
I’m using this website TikTokenizer to visualize tokenization of a sentence, you can try it out as well.
In the above sentence:
“hi how are you? Have you heard of Twentyone Pilots?”
You can see that we are using a tokenizer called “cl100k_base” and you can see the colour coding for each token. For example:
“hi” has a token ID of 6151
“ how” has a token ID of 1268 and so on
A Tokenizer is the one that tokenizes the text to numbers. There are different tokenizers and this is why I mentioned previously that there are a lot of ways to create these tokens. We will also write our own tokenizer from scratch in a future article to understand how this tokenizer works under the hood.
Don’t think too much on how it chooses to give a integer token ID, how its deciding which character, or word or subword to assign a token ID.
For now, just focus on understanding and visualizing that tokens are just some integers mapped to a character or subword or word.
Now, lets change the tokenizer to something else and see if the number of tokens and the token IDs are some or not:
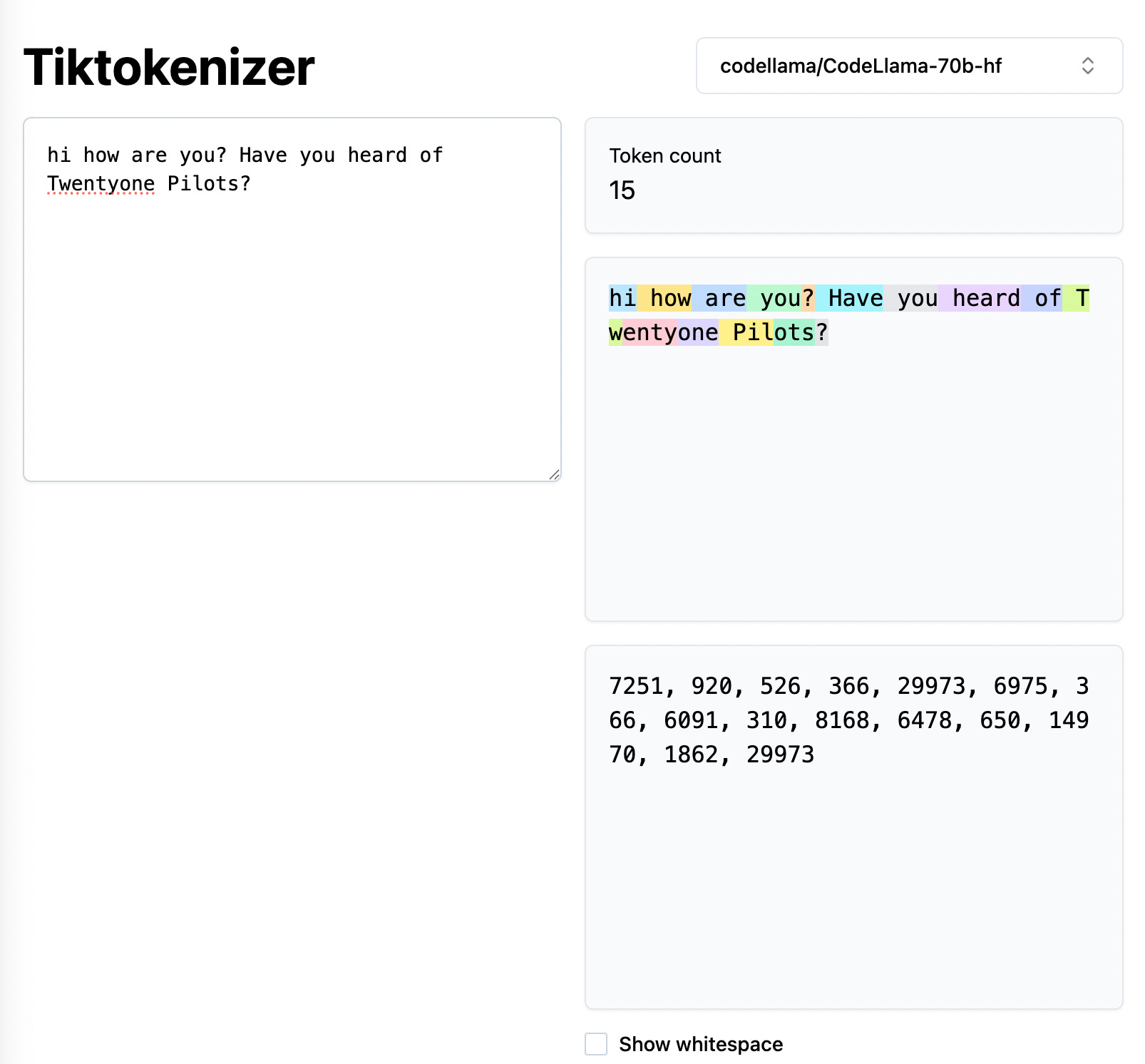
You can see, I changed the tokenizer on top right and now the token count increased to 15 from 14. The token IDs for characters or words or subwords are also different.
Now that we understood about tokens, lets now understand about the next thing, that is Embeddings.
Embedding
First, the text is converted into tokens, but LLMs work with embeddings, that’s why tokens must be converted into embeddings and then the LLMs actually work with the embeddings.
So what exactly is an embedding?
An embedding is a dense numeric representation of a token, basically a list of numbers (called a vector) that captures the meaning of that token.
Why do we need embeddings? Aren’t token IDs enough?
Token IDs are just arbitrary labels. For example, if “king” has token ID 1234 and “queen” has token ID 5678, there’s nothing about those numbers that tells us these words are related. They’re just random identifiers.
Embeddings solve this problem. Embeddings are actually much better than tokens because:
Embeddings capture meaning: Words with similar meanings get similar embeddings. So “king” and “queen” would have embeddings that are numerically close to each other, while “king” and “banana” would be far apart.
Embeddings are efficient: A single embedding (usually a vector of 256, 512, or more numbers) can represent complex semantic information about a token. This is way more powerful than just having a single token ID that doesn’t tell us anything about the word’s meaning or relationships.
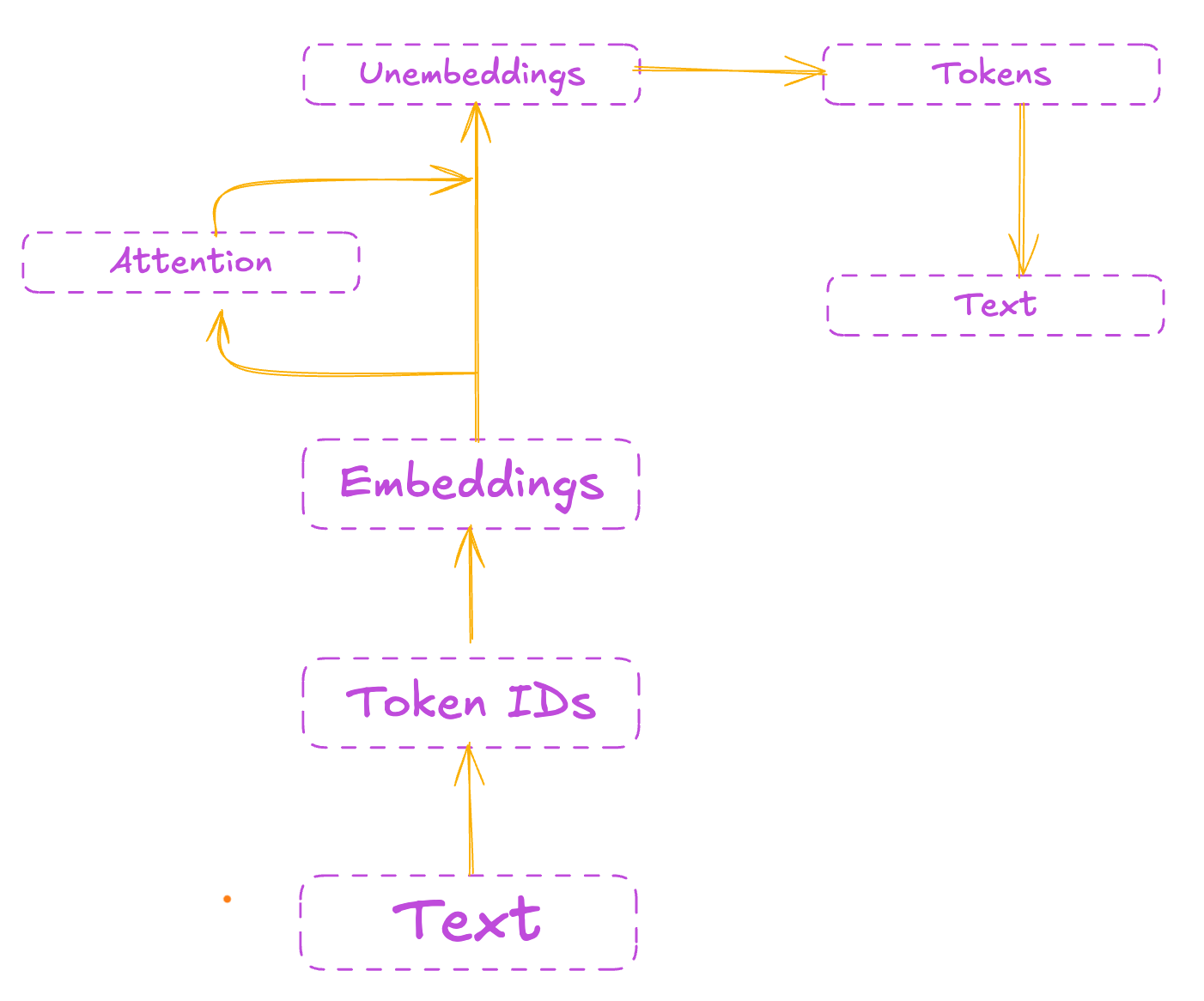
We start with human readable text, then the text gets converted into token IDs and then they are converted into embeddings, then the embedding vector goes to an un-embedding matrix that back transforms the embeddings into tokens, then these tokens gets converted to text.
You can see there is also an “Attention” mechanism, I’m not going explain that until we first understand tokenizer and embeddings in depth. We will learn about attention mechanism when we will start building our own LLM model. Just be patient
I know its a bit theoretical but from next article, we will start coding and learn concepts using python. We will learn much more about tokenizers and embeddings in future articles. Goodbye!